
|
Home | Libraries | People | FAQ | More |


Boost.MPI provides an alternative MPI interface from the Python
programming language via the boost.mpi module.
The Boost.MPI Python bindings, built on top of the C++ Boost.MPI using the
Boost.Python library,
provide nearly all of the functionality of Boost.MPI within a dynamic, object-oriented
language.
The Boost.MPI Python module can be built and installed from the libs/mpi/build directory.
Just follow the configuration and installation
instructions for the C++ Boost.MPI. Once you have installed the Python module,
be sure that the installation location is in your PYTHONPATH.
Getting started with the Boost.MPI Python module is as easy as importing
boost.mpi. Our first "Hello, World!"
program is just two lines long:
import boost.mpi as mpi print "I am process %d of %d." % (mpi.rank, mpi.size)
Go ahead and run this program with several processes. Be sure to invoke the
python interpreter from
mpirun, e.g.,
mpirun -np 5 python hello_world.py
This will return output such as:
I am process 1 of 5. I am process 3 of 5. I am process 2 of 5. I am process 4 of 5. I am process 0 of 5.
Point-to-point operations in Boost.MPI have nearly the same syntax in Python as in C++. We can write a simple two-process Python program that prints "Hello, world!" by transmitting Python strings:
import boost.mpi as mpi if mpi.world.rank == 0: mpi.world.send(1, 0, 'Hello') msg = mpi.world.recv(1, 1) print msg,'!' else: msg = mpi.world.recv(0, 0) print (msg + ', '), mpi.world.send(0, 1, 'world')
There are only a few notable differences between this Python code and the
example in the C++ tutorial. First
of all, we don't need to write any initialization code in Python: just loading
the boost.mpi module makes the appropriate MPI_Init and MPI_Finalize
calls. Second, we're passing Python objects from one process to another through
MPI. Any Python object that can be pickled can be transmitted; the next section
will describe in more detail how the Boost.MPI Python layer transmits objects.
Finally, when we receive objects with recv,
we don't need to specify the type because transmission of Python objects
is polymorphic.
When experimenting with Boost.MPI in Python, don't forget that help is always
available via pydoc: just
pass the name of the module or module entity on the command line (e.g.,
pydoc boost.mpi.communicator) to receive complete reference
documentation. When in doubt, try it!
Boost.MPI can transmit user-defined data in several different ways. Most importantly, it can transmit arbitrary Python objects by pickling them at the sender and unpickling them at the receiver, allowing arbitrarily complex Python data structures to interoperate with MPI.
Boost.MPI also supports efficient serialization and transmission of C++ objects
(that have been exposed to Python) through its C++ interface. Any C++ type
that provides (de-)serialization routines that meet the requirements of the
Boost.Serialization library is eligible for this optimization, but the type
must be registered in advance. To register a C++ type, invoke the C++ function
register_serialized.
If your C++ types come from other Python modules (they probably will!), those
modules will need to link against the boost_mpi
and boost_mpi_python libraries
as described in the installation section.
Note that you do not need to link against
the Boost.MPI Python extension module.
Finally, Boost.MPI supports separation of the structure of an object from the data it stores, allowing the two pieces to be transmitted separately. This "skeleton/content" mechanism, described in more detail in a later section, is a communication optimization suitable for problems with fixed data structures whose internal data changes frequently.
Boost.MPI supports all of the MPI collectives (scatter,
reduce, scan,
broadcast, etc.) for any
type of data that can be transmitted with the point-to-point communication
operations. For the MPI collectives that require a user-specified operation
(e.g., reduce and scan), the operation can be an arbitrary
Python function. For instance, one could concatenate strings with all_reduce:
mpi.all_reduce(my_string, lambda x,y: x + y)
The following module-level functions implement MPI collectives: all_gather Gather the values from all processes. all_reduce Combine the results from all processes. all_to_all Every process sends data to every other process. broadcast Broadcast data from one process to all other processes. gather Gather the values from all processes to the root. reduce Combine the results from all processes to the root. scan Prefix reduction of the values from all processes. scatter Scatter the values stored at the root to all processes.
Boost.MPI provides a skeleton/content mechanism that allows the transfer of large data structures to be split into two separate stages, with the skeleton (or, "shape") of the data structure sent first and the content (or, "data") of the data structure sent later, potentially several times, so long as the structure has not changed since the skeleton was transferred. The skeleton/content mechanism can improve performance when the data structure is large and its shape is fixed, because while the skeleton requires serialization (it has an unknown size), the content transfer is fixed-size and can be done without extra copies.
To use the skeleton/content mechanism from Python, you must first register
the type of your data structure with the skeleton/content mechanism from C++. The registration function is register_skeleton_and_content
and resides in the <boost/mpi/python.hpp>
header.
Once you have registered your C++ data structures, you can extract the skeleton
for an instance of that data structure with skeleton(). The resulting skeleton_proxy
can be transmitted via the normal send routine, e.g.,
mpi.world.send(1, 0, skeleton(my_data_structure))
skeleton_proxy objects can
be received on the other end via recv(), which stores a newly-created instance
of your data structure with the same "shape" as the sender in its
"object" attribute:
shape = mpi.world.recv(0, 0) my_data_structure = shape.object
Once the skeleton has been transmitted, the content (accessed via get_content) can be transmitted in much
the same way. Note, however, that the receiver also specifies get_content(my_data_structure)
in its call to receive:
if mpi.rank == 0: mpi.world.send(1, 0, get_content(my_data_structure)) else: mpi.world.recv(0, 0, get_content(my_data_structure))
Of course, this transmission of content can occur repeatedly, if the values in the data structure--but not its shape--changes.
The skeleton/content mechanism is a structured way to exploit the interaction
between custom-built MPI datatypes and MPI_BOTTOM,
to eliminate extra buffer copies.
Boost.MPI is a C++ library whose facilities have been exposed to Python via the Boost.Python library. Since the Boost.MPI Python bindings are build directly on top of the C++ library, and nearly every feature of C++ library is available in Python, hybrid C++/Python programs using Boost.MPI can interact, e.g., sending a value from Python but receiving that value in C++ (or vice versa). However, doing so requires some care. Because Python objects are dynamically typed, Boost.MPI transfers type information along with the serialized form of the object, so that the object can be received even when its type is not known. This mechanism differs from its C++ counterpart, where the static types of transmitted values are always known.
The only way to communicate between the C++ and Python views on Boost.MPI
is to traffic entirely in Python objects. For Python, this is the normal
state of affairs, so nothing will change. For C++, this means sending and
receiving values of type boost::python::object,
from the Boost.Python
library. For instance, say we want to transmit an integer value from Python:
comm.send(1, 0, 17)
In C++, we would receive that value into a Python object and then extract an integer value:
boost::python::object value; comm.recv(0, 0, value); int int_value = boost::python::extract<int>(value);
In the future, Boost.MPI will be extended to allow improved interoperability with the C++ Boost.MPI and the C MPI bindings.
The Boost.MPI Python module, boost.mpi,
has its own reference documentation,
which is also available using pydoc
(from the command line) or help(boost.mpi) (from the Python interpreter).
The design philosophy of the Parallel MPI library is very simple: be both
convenient and efficient. MPI is a library built for high-performance applications,
but it's FORTRAN-centric, performance-minded design makes it rather inflexible
from the C++ point of view: passing a string from one process to another
is inconvenient, requiring several messages and explicit buffering; passing
a container of strings from one process to another requires an extra level
of manual bookkeeping; and passing a map from strings to containers of strings
is positively infuriating. The Parallel MPI library allows all of these data
types to be passed using the same simple send() and recv() primitives. Likewise, collective operations
such as reduce() allow arbitrary data types
and function objects, much like the C++ Standard Library would.
The higher-level abstractions provided for convenience must not have an impact
on the performance of the application. For instance, sending an integer via
send must be as efficient
as a call to MPI_Send, which
means that it must be implemented by a simple call to MPI_Send;
likewise, an integer reduce()
using std::plus<int> must
be implemented with a call to MPI_Reduce
on integers using the MPI_SUM
operation: anything less will impact performance. In essence, this is the
"don't pay for what you don't use" principle: if the user is not
transmitting strings, s/he should not pay the overhead associated with strings.
Sometimes, achieving maximal performance means foregoing convenient abstractions and implementing certain functionality using lower-level primitives. For this reason, it is always possible to extract enough information from the abstractions in Boost.MPI to minimize the amount of effort required to interface between Boost.MPI and the C MPI library.
There are an increasing number of hybrid parallel applications that mix distributed
and shared memory parallelism. To know how to support that model, one need
to know what level of threading support is guaranteed by the MPI implementation.
There are 4 ordered level of possible threading support described by mpi::threading::level. At the
lowest level, you should not use threads at all, at the highest level, any
thread can perform MPI call.
If you want to use multi-threading in your MPI application, you should indicate in the environment constructor your preferred threading support. Then probe the one the library did provide, and decide what you can do with it (it could be nothing, then aborting is a valid option):
#include <boost/mpi/environment.hpp> #include <boost/mpi/communicator.hpp> #include <iostream> namespace mpi = boost::mpi; namespace mt = mpi::threading; int main() { mpi::environment env(mt::funneled); if (env.thread_level() < mt::funneled) { env.abort(-1); } mpi::communicator world; std::cout << "I am process " << world.rank() << " of " << world.size() << "." << std::endl; return 0; }
Message-passing performance is crucial in high-performance distributed computing. To evaluate the performance of Boost.MPI, we modified the standard NetPIPE benchmark (version 3.6.2) to use Boost.MPI and compared its performance against raw MPI. We ran five different variants of the NetPIPE benchmark:
MPI_BYTE)
rather than a fundamental datatype.
Char in place of the fundamental char type. The Char
type contains a single char,
a serialize()
method to make it serializable, and specializes is_mpi_datatype
to force Boost.MPI to build a derived MPI data type for it.
Char in place of the
fundamental char type. This
Char type contains a
single char and is serializable.
Unlike the Datatypes case, is_mpi_datatype
is not specialized, forcing Boost.MPI
to perform many, many serialization calls.
The actual tests were performed on the Odin cluster in the Department of Computer Science at Indiana University, which contains 128 nodes connected via Infiniband. Each node contains 4GB memory and two AMD Opteron processors. The NetPIPE benchmarks were compiled with Intel's C++ Compiler, version 9.0, Boost 1.35.0 (prerelease), and Open MPI version 1.1. The NetPIPE results follow:
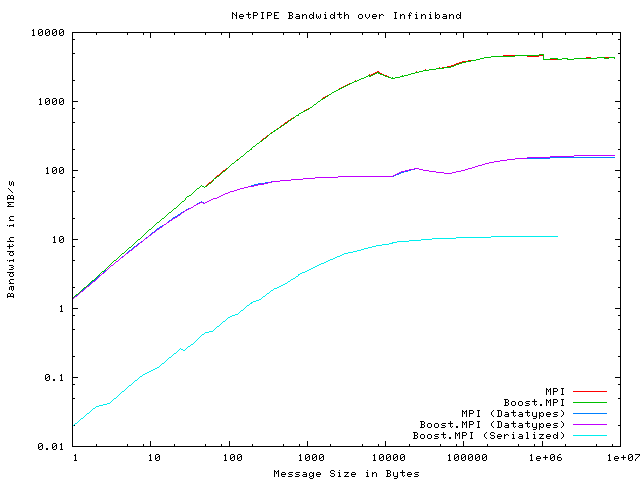
There are a some observations we can make about these NetPIPE results. First of all, the top two plots show that Boost.MPI performs on par with MPI for fundamental types. The next two plots show that Boost.MPI performs on par with MPI for derived data types, even though Boost.MPI provides a much more abstract, completely transparent approach to building derived data types than raw MPI. Overall performance for derived data types is significantly worse than for fundamental data types, but the bottleneck is in the underlying MPI implementation itself. Finally, when forcing Boost.MPI to serialize characters individually, performance suffers greatly. This particular instance is the worst possible case for Boost.MPI, because we are serializing millions of individual characters. Overall, the additional abstraction provided by Boost.MPI does not impair its performance.
environment
Boost.MPI was developed with support from Zurcher Kantonalbank. Daniel Egloff and Michael Gauckler contributed many ideas to Boost.MPI's design, particularly in the design of its abstractions for MPI data types and the novel skeleton/context mechanism for large data structures. Prabhanjan (Anju) Kambadur developed the predecessor to Boost.MPI that proved the usefulness of the Serialization library in an MPI setting and the performance benefits of specialization in a C++ abstraction layer for MPI. Jeremy Siek managed the formal review of Boost.MPI.