| Top |
Character Set ConversionCharacter Set Conversion — convert strings between different character sets |
| gchar * | g_convert () |
| gchar * | g_convert_with_fallback () |
| gchar * | g_convert_with_iconv () |
| GIConv | g_iconv_open () |
| gsize | g_iconv () |
| gint | g_iconv_close () |
| gchar * | g_locale_to_utf8 () |
| gchar * | g_filename_to_utf8 () |
| gchar * | g_filename_from_utf8 () |
| gboolean | g_get_filename_charsets () |
| gchar * | g_filename_display_name () |
| gchar * | g_filename_display_basename () |
| gchar * | g_locale_from_utf8 () |
| gboolean | g_get_charset () |
| gchar * | g_get_codeset () |
The g_convert() family of function wraps the functionality of iconv().
In addition to pure character set conversions, GLib has functions to
deal with the extra complications of encodings for file names.
Historically, UNIX has not had a defined encoding for file names: a file name is valid as long as it does not have path separators in it ("/"). However, displaying file names may require conversion: from the character set in which they were created, to the character set in which the application operates. Consider the Spanish file name "Presentación.sxi". If the application which created it uses ISO-8859-1 for its encoding,
1 2 |
Character: P r e s e n t a c i ó n . s x i Hex code: 50 72 65 73 65 6e 74 61 63 69 f3 6e 2e 73 78 69 |
However, if the application use UTF-8, the actual file name on disk would look like this:
1 2 |
Character: P r e s e n t a c i ó n . s x i Hex code: 50 72 65 73 65 6e 74 61 63 69 c3 b3 6e 2e 73 78 69 |
Glib uses UTF-8 for its strings, and GUI toolkits like GTK+ that use
Glib do the same thing. If you get a file name from the file system,
for example, from readdir() or from g_dir_read_name(), and you wish
to display the file name to the user, you will need to convert it
into UTF-8. The opposite case is when the user types the name of a
file he wishes to save: the toolkit will give you that string in
UTF-8 encoding, and you will need to convert it to the character
set used for file names before you can create the file with open()
or fopen().
By default, Glib assumes that file names on disk are in UTF-8
encoding. This is a valid assumption for file systems which
were created relatively recently: most applications use UTF-8
encoding for their strings, and that is also what they use for
the file names they create. However, older file systems may
still contain file names created in "older" encodings, such as
ISO-8859-1. In this case, for compatibility reasons, you may want
to instruct Glib to use that particular encoding for file names
rather than UTF-8. You can do this by specifying the encoding for
file names in the G_FILENAME_ENCODING
environment variable. For example, if your installation uses
ISO-8859-1 for file names, you can put this in your ~/.profile
1 |
export G_FILENAME_ENCODING=ISO-8859-1 |
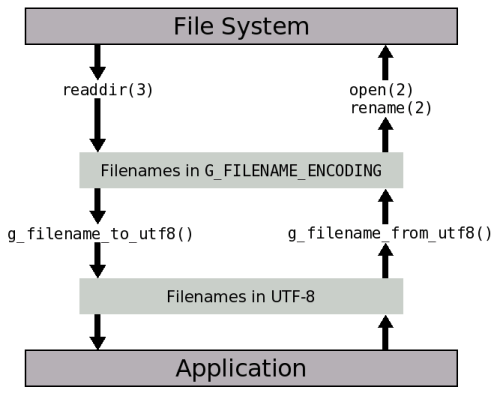
Glib provides the functions g_filename_to_utf8() and
g_filename_from_utf8() to perform the necessary conversions.
These functions convert file names from the encoding specified
in G_FILENAME_ENCODING to UTF-8 and vice-versa. This
diagram illustrates how
these functions are used to convert between UTF-8 and the
encoding for file names in the file system.
This section is a practical summary of the detailed
things to do to make sure your applications process file name encodings correctly.
If you get a file name from the file system from a function
such as readdir() or gtk_file_chooser_get_filename(), you do
not need to do any conversion to pass that file name to
functions like open(), rename(), or fopen() -- those are "raw"
file names which the file system understands.
If you need to display a file name, convert it to UTF-8 first
by using g_filename_to_utf8(). If conversion fails, display a
string like "Unknown file name". Do not convert this string back
into the encoding used for file names if you wish to pass it to
the file system; use the original file name instead.
For example, the document window of a word processor could display
"Unknown file name" in its title bar but still let the user save
the file, as it would keep the raw file name internally. This
can happen if the user has not set the G_FILENAME_ENCODING
environment variable even though he has files whose names are
not encoded in UTF-8.
If your user interface lets the user type a file name for saving
or renaming, convert it to the encoding used for file names in
the file system by using g_filename_from_utf8(). Pass the converted
file name to functions like fopen(). If conversion fails, ask the
user to enter a different file name. This can happen if the user
types Japanese characters when G_FILENAME_ENCODING is set to
ISO-8859-1, for example.
gchar * g_convert (const gchar *str,gssize len,const gchar *to_codeset,const gchar *from_codeset,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string from one character set to another.
Note that you should use g_iconv() for streaming conversions.
Despite the fact that byes_read
can return information about partial
characters, the g_convert_... functions are not generally suitable
for streaming. If the underlying converter maintains internal state,
then this won't be preserved across successive calls to g_convert(),
g_convert_with_iconv() or g_convert_with_fallback(). (An example of
this is the GNU C converter for CP1255 which does not emit a base
character until it knows that the next character is not a mark that
could combine with the base character.)
Using extensions such as "//TRANSLIT" may not work (or may not work
well) on many platforms. Consider using g_str_to_ascii() instead.
str |
the string to convert |
|
len |
the length of the string in bytes, or -1 if the string is
nul-terminated (Note that some encodings may allow nul
bytes to occur inside strings. In that case, using -1
for the |
|
to_codeset |
name of character set into which to convert |
|
from_codeset |
character set of |
|
bytes_read |
location to store the number of bytes in the
input string that were successfully converted, or |
[out] |
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
[out] |
error |
location to store the error occurring, or |
gchar * g_convert_with_fallback (const gchar *str,gssize len,const gchar *to_codeset,const gchar *from_codeset,const gchar *fallback,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string from one character set to another, possibly
including fallback sequences for characters not representable
in the output. Note that it is not guaranteed that the specification
for the fallback sequences in fallback
will be honored. Some
systems may do an approximate conversion from from_codeset
to to_codeset
in their iconv() functions,
in which case GLib will simply return that approximate conversion.
Note that you should use g_iconv() for streaming conversions.
Despite the fact that byes_read
can return information about partial
characters, the g_convert_... functions are not generally suitable
for streaming. If the underlying converter maintains internal state,
then this won't be preserved across successive calls to g_convert(),
g_convert_with_iconv() or g_convert_with_fallback(). (An example of
this is the GNU C converter for CP1255 which does not emit a base
character until it knows that the next character is not a mark that
could combine with the base character.)
str |
the string to convert |
|
len |
the length of the string in bytes, or -1 if the string is
nul-terminated (Note that some encodings may allow nul
bytes to occur inside strings. In that case, using -1
for the |
|
to_codeset |
name of character set into which to convert |
|
from_codeset |
character set of |
|
fallback |
UTF-8 string to use in place of character not
present in the target encoding. (The string must be
representable in the target encoding).
If |
|
bytes_read |
location to store the number of bytes in the
input string that were successfully converted, or |
|
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
|
error |
location to store the error occurring, or |
gchar * g_convert_with_iconv (const gchar *str,gssize len,GIConv converter,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string from one character set to another.
Note that you should use g_iconv() for streaming conversions.
Despite the fact that byes_read
can return information about partial
characters, the g_convert_... functions are not generally suitable
for streaming. If the underlying converter maintains internal state,
then this won't be preserved across successive calls to g_convert(),
g_convert_with_iconv() or g_convert_with_fallback(). (An example of
this is the GNU C converter for CP1255 which does not emit a base
character until it knows that the next character is not a mark that
could combine with the base character.)
str |
the string to convert |
|
len |
the length of the string in bytes, or -1 if the string is
nul-terminated (Note that some encodings may allow nul
bytes to occur inside strings. In that case, using -1
for the |
|
converter |
conversion descriptor from |
|
bytes_read |
location to store the number of bytes in the
input string that were successfully converted, or |
|
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
|
error |
location to store the error occurring, or |
GIConv g_iconv_open (const gchar *to_codeset,const gchar *from_codeset);
Same as the standard UNIX routine iconv_open(), but
may be implemented via libiconv on UNIX flavors that lack
a native implementation.
GLib provides g_convert() and g_locale_to_utf8() which are likely
more convenient than the raw iconv wrappers.
gsize g_iconv (GIConv converter,gchar **inbuf,gsize *inbytes_left,gchar **outbuf,gsize *outbytes_left);
Same as the standard UNIX routine iconv(), but
may be implemented via libiconv on UNIX flavors that lack
a native implementation.
GLib provides g_convert() and g_locale_to_utf8() which are likely
more convenient than the raw iconv wrappers.
converter |
conversion descriptor from |
|
inbuf |
bytes to convert |
|
inbytes_left |
inout parameter, bytes remaining to convert in |
|
outbuf |
converted output bytes |
|
outbytes_left |
inout parameter, bytes available to fill in |
gint
g_iconv_close (GIConv converter);
Same as the standard UNIX routine iconv_close(), but
may be implemented via libiconv on UNIX flavors that lack
a native implementation. Should be called to clean up
the conversion descriptor from g_iconv_open() when
you are done converting things.
GLib provides g_convert() and g_locale_to_utf8() which are likely
more convenient than the raw iconv wrappers.
gchar * g_locale_to_utf8 (const gchar *opsysstring,gssize len,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string which is in the encoding used for strings by the C runtime (usually the same as that used by the operating system) in the current locale into a UTF-8 string.
opsysstring |
a string in the encoding of the current locale. On Windows this means the system codepage. |
|
len |
the length of the string, or -1 if the string is
nul-terminated (Note that some encodings may allow nul
bytes to occur inside strings. In that case, using -1
for the |
|
bytes_read |
location to store the number of bytes in the
input string that were successfully converted, or |
[out][optional] |
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
[out][optional] |
error |
location to store the error occurring, or |
A newly-allocated buffer containing the converted string,
or NULL on an error, and error will be set.
gchar * g_filename_to_utf8 (const gchar *opsysstring,gssize len,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string which is in the encoding used by GLib for filenames into a UTF-8 string. Note that on Windows GLib uses UTF-8 for filenames; on other platforms, this function indirectly depends on the current locale.
opsysstring |
a string in the encoding for filenames. |
[type filename] |
len |
the length of the string, or -1 if the string is
nul-terminated (Note that some encodings may allow nul
bytes to occur inside strings. In that case, using -1
for the |
|
bytes_read |
location to store the number of bytes in the
input string that were successfully converted, or |
[out][optional] |
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
[out][optional] |
error |
location to store the error occurring, or |
gchar * g_filename_from_utf8 (const gchar *utf8string,gssize len,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string from UTF-8 to the encoding GLib uses for filenames. Note that on Windows GLib uses UTF-8 for filenames; on other platforms, this function indirectly depends on the current locale.
utf8string |
a UTF-8 encoded string. |
|
len |
the length of the string, or -1 if the string is nul-terminated. |
|
bytes_read |
location to store the number of bytes in
the input string that were successfully converted, or |
[out][optional] |
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
[out] |
error |
location to store the error occurring, or |
The converted string, or NULL on an error.
[array length=bytes_written][element-type guint8][transfer full]
gboolean
g_get_filename_charsets (const gchar ***charsets);
Determines the preferred character sets used for filenames.
The first character set from the charsets
is the filename encoding, the
subsequent character sets are used when trying to generate a displayable
representation of a filename, see g_filename_display_name().
On Unix, the character sets are determined by consulting the
environment variables G_FILENAME_ENCODING and G_BROKEN_FILENAMES.
On Windows, the character set used in the GLib API is always UTF-8
and said environment variables have no effect.
G_FILENAME_ENCODING may be set to a comma-separated list of
character set names. The special token "@locale" is taken
to mean the character set for the current locale.
If G_FILENAME_ENCODING is not set, but G_BROKEN_FILENAMES is,
the character set of the current locale is taken as the filename
encoding. If neither environment variable is set, UTF-8 is taken
as the filename encoding, but the character set of the current locale
is also put in the list of encodings.
The returned charsets
belong to GLib and must not be freed.
Note that on Unix, regardless of the locale character set or
G_FILENAME_ENCODING value, the actual file names present
on a system might be in any random encoding or just gibberish.
Since: 2.6
gchar *
g_filename_display_name (const gchar *filename);
Converts a filename into a valid UTF-8 string. The conversion is
not necessarily reversible, so you should keep the original around
and use the return value of this function only for display purposes.
Unlike g_filename_to_utf8(), the result is guaranteed to be non-NULL
even if the filename actually isn't in the GLib file name encoding.
If GLib cannot make sense of the encoding of filename
, as a last resort it
replaces unknown characters with U+FFFD, the Unicode replacement character.
You can search the result for the UTF-8 encoding of this character (which is
"\357\277\275" in octal notation) to find out if filename
was in an invalid
encoding.
If you know the whole pathname of the file you should use
g_filename_display_basename(), since that allows location-based
translation of filenames.
Since: 2.6
gchar *
g_filename_display_basename (const gchar *filename);
Returns the display basename for the particular filename, guaranteed to be valid UTF-8. The display name might not be identical to the filename, for instance there might be problems converting it to UTF-8, and some files can be translated in the display.
If GLib cannot make sense of the encoding of filename
, as a last resort it
replaces unknown characters with U+FFFD, the Unicode replacement character.
You can search the result for the UTF-8 encoding of this character (which is
"\357\277\275" in octal notation) to find out if filename
was in an invalid
encoding.
You must pass the whole absolute pathname to this functions so that translation of well known locations can be done.
This function is preferred over g_filename_display_name() if you know the
whole path, as it allows translation.
a newly allocated string containing a rendition of the basename of the filename in valid UTF-8
Since: 2.6
gchar * g_locale_from_utf8 (const gchar *utf8string,gssize len,gsize *bytes_read,gsize *bytes_written,GError **error);
Converts a string from UTF-8 to the encoding used for strings by the C runtime (usually the same as that used by the operating system) in the current locale. On Windows this means the system codepage.
utf8string |
a UTF-8 encoded string |
|
len |
the length of the string, or -1 if the string is
nul-terminated (Note that some encodings may allow nul
bytes to occur inside strings. In that case, using -1
for the |
|
bytes_read |
location to store the number of bytes in the
input string that were successfully converted, or |
[out][optional] |
bytes_written |
the number of bytes stored in the output buffer (not including the terminating nul). |
[out][optional] |
error |
location to store the error occurring, or |
A newly-allocated buffer containing the converted string,
or NULL on an error, and error will be set.
gboolean
g_get_charset (const char **charset);
Obtains the character set for the current locale; you
might use this character set as an argument to g_convert(), to convert
from the current locale's encoding to some other encoding. (Frequently
g_locale_to_utf8() and g_locale_from_utf8() are nice shortcuts, though.)
On Windows the character set returned by this function is the so-called system default ANSI code-page. That is the character set used by the "narrow" versions of C library and Win32 functions that handle file names. It might be different from the character set used by the C library's current locale.
The return value is TRUE if the locale's encoding is UTF-8, in that
case you can perhaps avoid calling g_convert().
The string returned in charset
is not allocated, and should not be
freed.
typedef struct _GIConv GIConv;
The GIConv struct wraps an iconv() conversion descriptor. It contains
private data and should only be accessed using the following functions.
#define G_CONVERT_ERROR g_convert_error_quark()
Error domain for character set conversions. Errors in this domain will be from the GConvertError enumeration. See GError for information on error domains.
Error codes returned by character set conversion routines.